
Data Structure Utilities
- slice
- range and xrange
- bisect
- sort
- sorted
- reversed
- enumerate
- zip
- list comprehensions
slice
Slice selects a section of list types (arrays, tuples, NumPy arrays) with its arguments [start:end]: start is included, end is not. The number of elements in the result is stop - end.
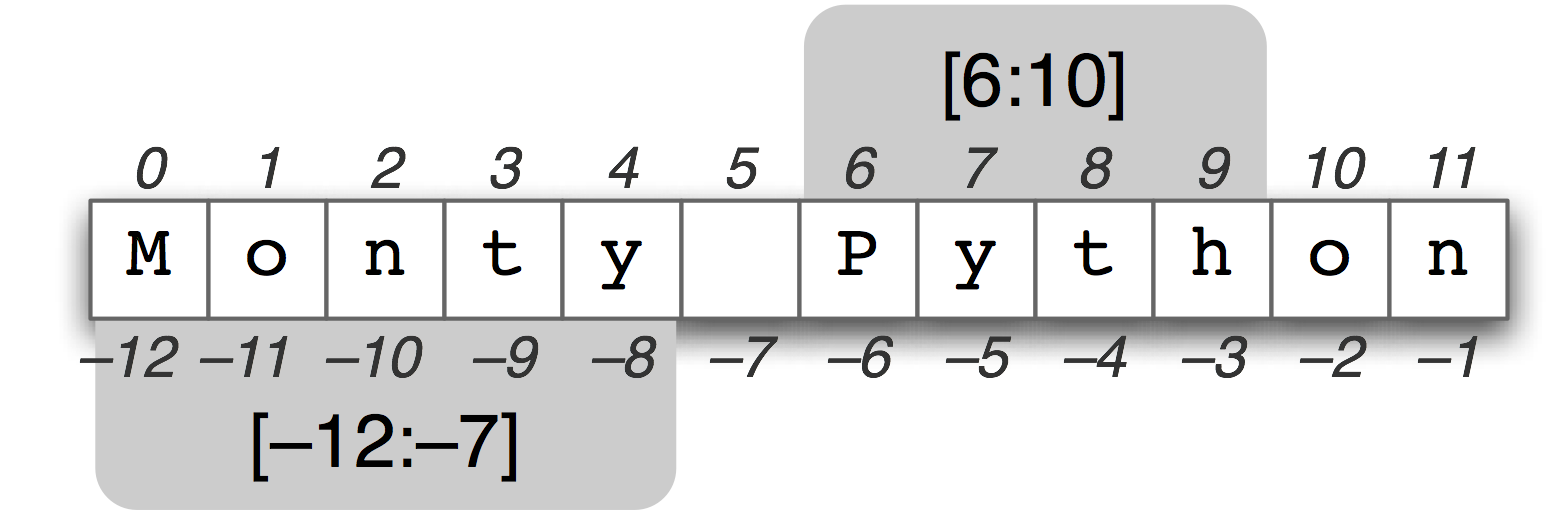
Image source: http://www.nltk.org/images/string-slicing.png
Slice 4 elements starting at index 6 and ending at index 9:
seq = 'Monty Python'
seq[6:10]
'Pyth'
Omit start to default to start of the sequence:
seq[:5]
'Monty'
Omit end to default to end of the sequence:
seq[6:]
'Python'
Negative indices slice relative to the end:
seq[-12:-7]
'Monty'
Slice can also take a step [start:end:step].
Get every other element:
seq[::2]
'MnyPto'
Passing -1 for the step reverses the list or tuple:
seq[::-1]
'nohtyP ytnoM'
You can assign elements to a slice (note the slice range does not have to equal number of elements to assign):
seq = [1, 1, 2, 3, 5, 8, 13]
seq[5:] = ['H', 'a', 'l', 'l']
seq
[1, 1, 2, 3, 5, 'H', 'a', 'l', 'l']
Compare the output of assigning into a slice (above) versus the output of assigning into an index (below):
seq = [1, 1, 2, 3, 5, 8, 13]
seq[5] = ['H', 'a', 'l', 'l']
seq
[1, 1, 2, 3, 5, ['H', 'a', 'l', 'l'], 13]
range and xrange
Generate a list of evenly spaced integers with range or xrange. Note: range in Python 3 returns a generator and xrange is not available.
Generate 10 integers:
range(10)
[0, 1, 2, 3, 4, 5, 6, 7, 8, 9]
Range can take start, stop, and step arguments:
range(0, 20, 3)
[0, 3, 6, 9, 12, 15, 18]
It is very common to iterate through sequences by index with range:
seq = [1, 2, 3]
for i in range(len(seq)):
val = seq[i]
print(val)
1
2
3
For longer ranges, xrange is recommended and is available in Python 3 as range. It returns an iterator that generates integers one by one rather than all at once and storing them in a large list.
sum = 0
for i in xrange(100000):
if i % 2 == 0:
sum += 1
print(sum)
50000
bisect
The bisect module does not check whether the list is sorted, as this check would be expensive O(n). Using bisect on an unsorted list will not result in an error but could lead to incorrect results.
import bisect
Find the location where an element should be inserted to keep the list sorted:
seq = [1, 2, 2, 3, 5, 13]
bisect.bisect(seq, 8)
5
Insert an element into a location to keep the list sorted:
bisect.insort(seq, 8)
seq
[1, 2, 2, 3, 5, 8, 13]
sort
Sort in-place O(n log n)
seq = [1, 5, 3, 9, 7, 6]
seq.sort()
seq
[1, 3, 5, 6, 7, 9]
Sort by the secondary key of str length:
seq = ['the', 'quick', 'brown', 'fox', 'jumps', 'over']
seq.sort(key=len)
seq
['the', 'fox', 'over', 'quick', 'brown', 'jumps']
sorted
Return a new sorted list from the elements of a sequence O(n log n):
sorted([2, 5, 1, 8, 7, 9])
[1, 2, 5, 7, 8, 9]
sorted('foo bar baz')
[' ', ' ', 'a', 'a', 'b', 'b', 'f', 'o', 'o', 'r', 'z']
It's common to get a sorted list of unique elements by combining sorted and set:
seq = [2, 5, 1, 8, 7, 9, 9, 2, 5, 1, (4, 2), (1, 2), (1, 2)]
sorted(set(seq))
[1, 2, 5, 7, 8, 9, (1, 2), (4, 2)]
reversed
Iterate over the sequence elements in reverse order:
list(reversed(seq))
[(1, 2), (1, 2), (4, 2), 1, 5, 2, 9, 9, 7, 8, 1, 5, 2]
enumerate
Get the index of a collection and the value:
strings = ['foo', 'bar', 'baz']
for i, string in enumerate(strings):
print(i, string)
(0, 'foo')
(1, 'bar')
(2, 'baz')
zip
Pair up the elements of sequences to create a list of tuples:
seq_1 = [1, 2, 3]
seq_2 = ['foo', 'bar', 'baz']
zip(seq_1, seq_2)
[(1, 'foo'), (2, 'bar'), (3, 'baz')]
Zip takes an arbitrary number of sequences. The number of elements it produces is determined by the shortest sequence:
seq_3 = [True, False]
zip(seq_1, seq_2, seq_3)
[(1, 'foo', True), (2, 'bar', False)]
It is common to use zip for simultaneously iterating over multiple sequences combined with enumerate:
for i, (a, b) in enumerate(zip(seq_1, seq_2)):
print('%d: %s, %s' % (i, a, b))
0: 1, foo
1: 2, bar
2: 3, baz
Zip can unzip a zipped sequence, which you can think of as converting a list of rows into a list of columns:
numbers = [(1, 'one'), (2, 'two'), (3, 'three')]
a, b = zip(*numbers)
a
(1, 2, 3)
b
('one', 'two', 'three')
List Comprehensions
List comprehensions concisely form a new list by filtering the elements of a sequence and transforming the elements passing the filter. List comprehensions take the form:
[expr for val in collection if condition]
Which is equivalent to the following for loop:
result = []
for val in collection:
if condition:
result.append(expr)
Convert to upper case all strings that start with a 'b':
strings = ['foo', 'bar', 'baz', 'f', 'fo', 'b', 'ba']
[x.upper() for x in strings if x[0] == 'b']
['BAR', 'BAZ', 'B', 'BA']
List comprehensions can be nested:
list_of_tuples = [(1, 2, 3), (4, 5, 6), (7, 8, 9)]
[x for tup in list_of_tuples for x in tup]
[1, 2, 3, 4, 5, 6, 7, 8, 9]
Dict Comprehension
A dict comprehension is similar to a list comprehension but returns a dict.
Create a mapping of strings and their locations in the list for strings that start with a 'b':
{index : val for index, val in enumerate(strings) if val[0] == 'b'}
{1: 'bar', 2: 'baz', 5: 'b', 6: 'ba'}
Set Comprehension
A set comprehension is similar to a list comprehension but returns a set.
Get the unique lengths of strings that start with a 'b':
{len(x) for x in strings if x[0] == 'b'}
{1, 2, 3}